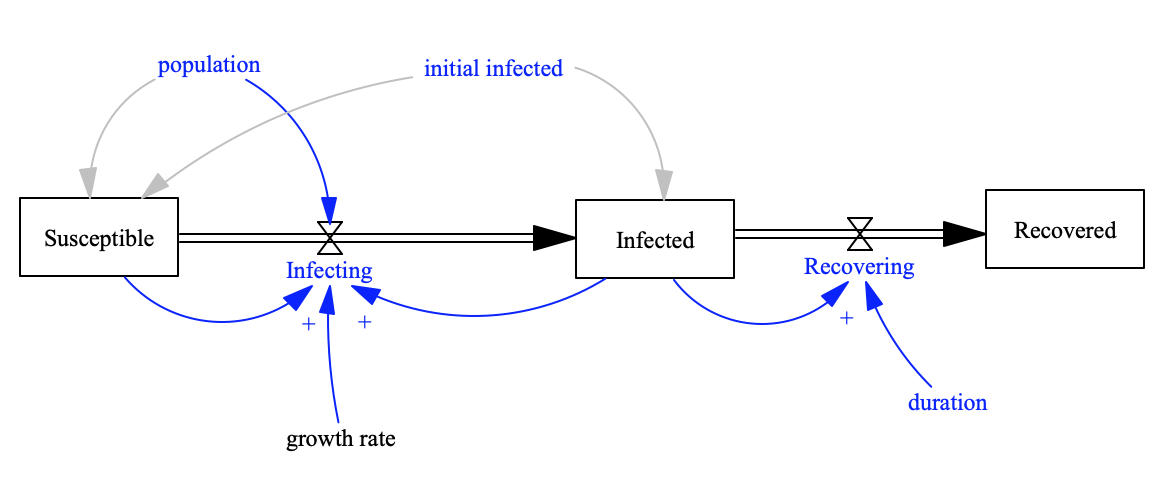
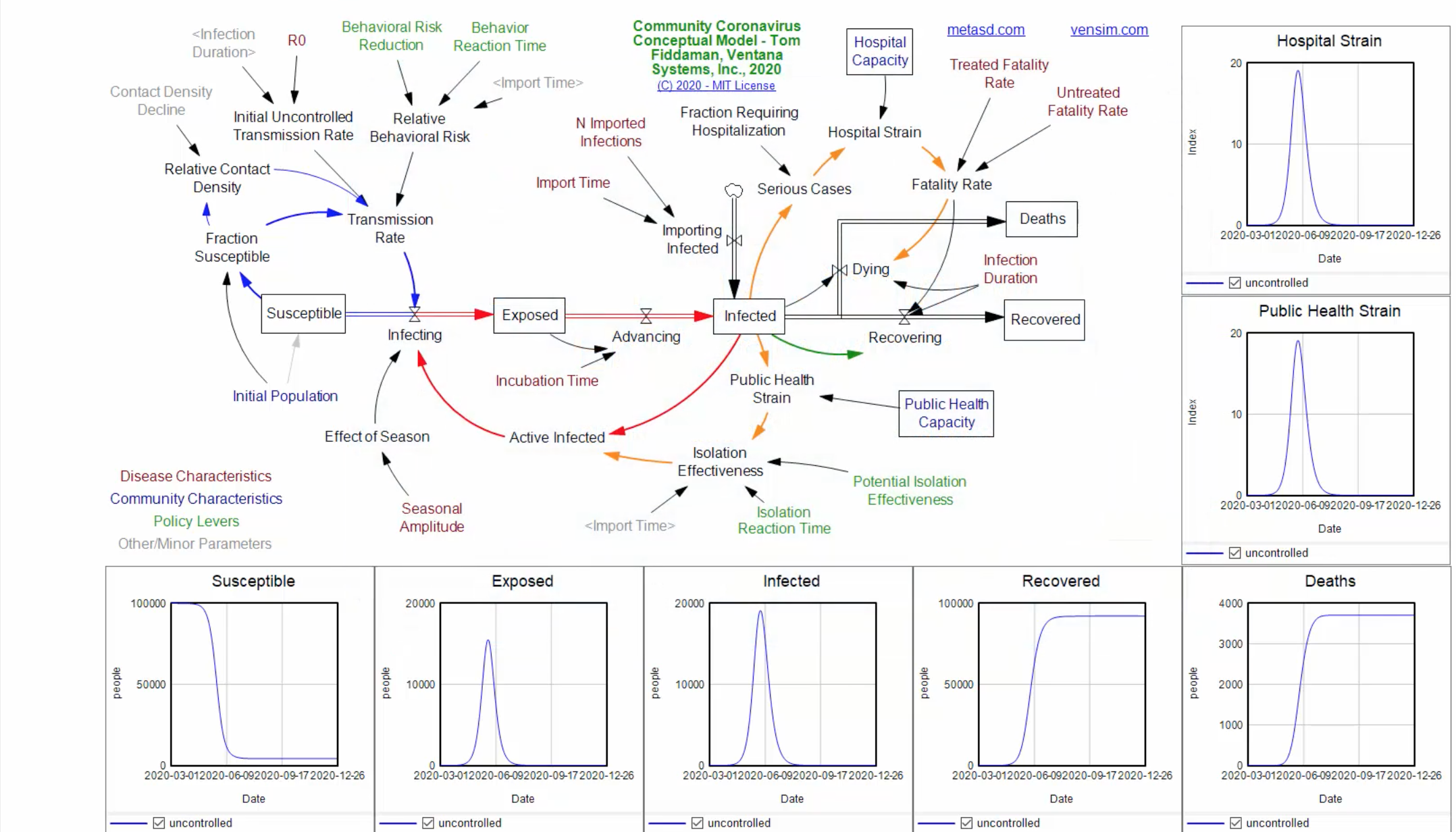
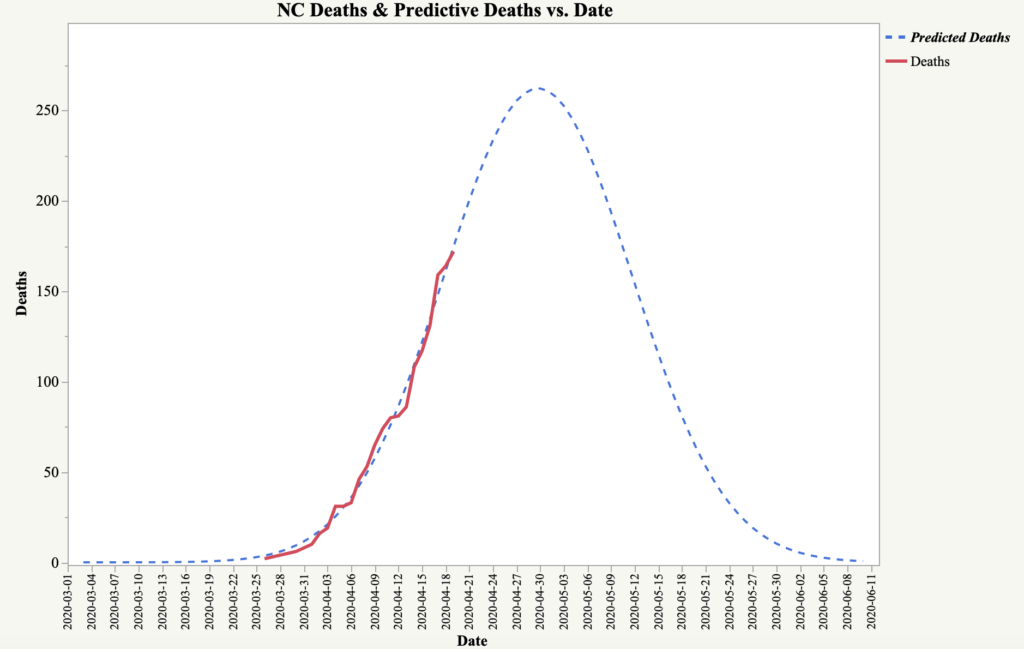
In my previous post, I discussed models that can be used to forecast the future behavior of the pandemic. One of the limitations of these models is that they are complex and need to be recalibrated or updated frequently. What would be helpful is an analysis technique that would allow us to monitor various factors on a daily basis to know when a change in the situation is likely. For this purpose, we turn our attention to an approach known as Statistical Process Control (SPC) which was introduced to the industrial community by Walter Shewhart in the mid-1920s.
In SPC, the amount of variation that has transpired over time is used to derive upper and lower limits of activity expected. Unlike other statistical approaches, SPC accounts for the notion that processes happen over time, and in addition to the variability that is seen in the aggregate data, it is important to consider the amount of variability in the data over time. This is best understood by looking at an example. The following SPC chart depicts the daily count of COVID-19 deaths for the state of North Carolina.
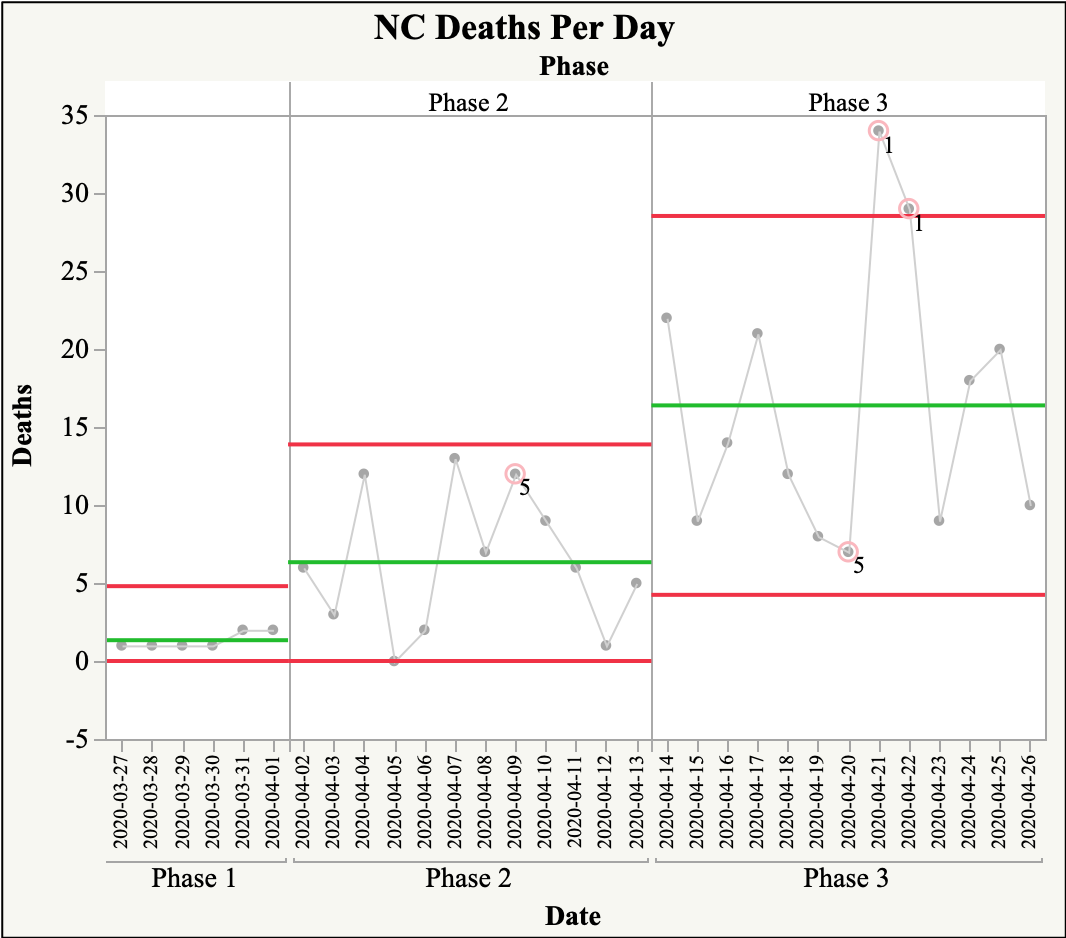
As you can see, there are points that are beyond the upper control limit in Phase 3. These points are referred to as special cause points. These points are beyond the range of deaths which might be expected currently. For these points, it would be appropriate to question whether there was a specific precursor that caused these results. With there being so many factors that could lead to these spurts it may not be possible to identify a specific cause. However, that does not detract from our ability to understand the amount of variation which may be expected in the count of daily death, which could help policymakers from reacting to changes too quickly.
Another type of SPC chart that can be used to provide valuable information to policymakers during the time of a pandemic is one that is based on rates such as the example below.

This later chart can be useful when trying to compare multiple rates as it controls for the number of opportunities or sample size, and as such is a more equitable way of comparing multiple rates.
Over the past four posts, I have described a number of models that can be used to assess the trajectory and health impact of COVID-19. As is evident from these discussions, there is a great deal of variability in the data related to this pandemic and an assortment of factors to consider when interpreting this data. With this in mind, it is important to consider all of these factors before making a decision regarding the reopening of communities. In future posts, I will begin to look at some of the actions that need to be taken as we reopen.